Parasitic open interest
Parasitic open interest is when an application tries to use an oracle game price without paying for the oracle game. This creates two incentives: delay and censorship. The censorship risk is addressed above — contrived oracle games exploit the parasitic OI out of existence. To the extent parasitic open interest dodges censorship risk, it can actually benefit the parties that paid for the oracle game. For example, in a lending-style liquidation setup, the oracle game can feature protocol fees. A 1% protocol fee per round can be directed to a address specified at oracle game creation — a smart contract designed to split accrued fees between the lender and borrower who paid for the oracle game. The delay incentive for liquidation is, as a one-step heuristic framed in probability times payoff terms:
where the payoff is the liquidation penalty, is the liquidation price, is the price at settlement time, and the cost to delay the oracle is approximately 1% of the oracle game size at that round. If the parasitic open interest is very large, the cost to delay is small relative to the payoff, but since the initial oracle liquidity was a function of the non-parasitic open interest to begin with (say 10%), the exponential fees in expectation can more than cover the delay. For example, with , the oracle game becomes larger than the paying notional in 4 rounds of delay (10% 20% 40% 80% 160%), paying 1% each time split between the original borrower and lender (0.1% 0.2% 0.4% 0.8% 1.6% and so on, as a percentage of paying notional).
Linear notional manipulation
Manipulation without a swap fee
Assume zero swap fees, protocol fees, and gas fees. Assume the manipulator always front-runs any other disputers and ends up on-chain first (this assumption is relaxed in the stronger form below). Assume a normal distribution. Also, unless otherwise noted, assume zero censorship. The manipulator is trying to bias the settled oracle price as much as possible in their favor. For linear notionals, generally it’s preferable to have ~0 fees and low multipliers in the oracle game since this maximizes oracle accuracy.Distributional robustness
We use normal distributions below for tractability. The key quantities for manipulation bounds are honest dispute barriers, DNT survival, and conditional mean settled bias. Across tested families, results are directionally similar in the relevant parameter range: volatility scale is typically the dominant driver, while distribution shape can shift the maximizing barrier and survival probabilities. In our tests, these shape effects usually did not increase the core bound for linear notionals. See Oracle Accuracy & Cost for further discussion.Wrong-price reporting
From Oracle Accuracy & Cost, the no-dispute band is . Assume , implying the honest dispute barriers are approximately . We will use a slightly wider for conservatism. A manipulator opening a long wants to settle the oracle price as low as possible relative to the true price. We call the mean difference between these two prices extraction. Strategy 1: Place wrong price and update. The manipulator places a price some above the lower dispute barrier. If the true price rises by just under , the manipulator updates their report higher before the honest dispute network can profitably dispute. If the true price falls by approximately standard deviations, the manipulator places a new price above the lower barrier from the current price. The extractable value is modeled as a barrier game with upper barrier at and lower barrier at . The per-round survival probability is the DNT (double-no-touch) probability for these barriers, and expected rounds to settlement is . The number of rounds is minimized (and survival maximized) when the barriers are centered on the true price, i.e. where . At this point the reported price is below true, and by symmetry the conditional mean price given survival is 0. So the expected extraction at settlement is simply . This approximately holds for any choice of . In the low-survival regime produced by these barrier widths, the conditional mean of the true price given survival (DNT) in an interval converges to the midpoint of the interval. Our barriers are at , so the conditional mean is . The extraction is then the conditional mean minus the reported price: . As moves away from , the reported price gets farther from true (more potential extraction), but the conditional mean shifts in the same direction by the same amount, nearly offsetting it. Extraction is approximately in this regime, while expected rounds increase as moves away from . For equal-width barriers, asymmetric placement (starting point not at the midpoint) strictly lowers the per-round survival probability compared to symmetric placement, strictly increasing expected rounds with little to no extraction gain. For , even the best-case gives a very small per-round survival probability, meaning many rounds are needed. The sim confirms this: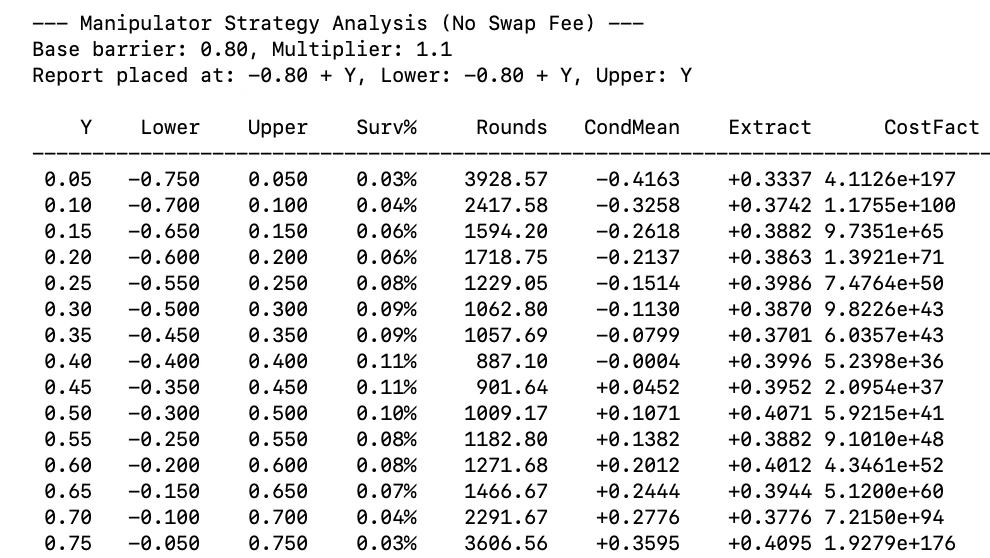
 The sim confirms extraction is near zero for all choices of . This strategy does not seem worth pursuing given near-zero extraction.
The sim confirms extraction is near zero for all choices of . This strategy does not seem worth pursuing given near-zero extraction.
Stronger form: true-price delay / timer refresh
The stronger-form manipulation strategy is: report the true price each round, and dispute exactly when delaying has higher utility than settling (), which we define as “favorable” vs “unfavorable.” This is a stopping-time game with first-passage probabilities (DNT), escalating round size, and endogenous stop decisions. We attempt to approximate this optimal control problem numerically below. The analysis is nontrivial and the numerical results should be treated as approximate. Assume the manipulator is opening a long with some external notional and wants the settled oracle price lower than the true price in a way that maximizes their expected value, and the counterparty is passive. The manipulator can either delay the game or let it settle, depending on which decision is worth more. Unlike the wrong-price strategies above, the front-running assumption is relaxed here: we assume the honest network gets disputes across at their standard barriers. Let be the price error in sigma units at the moment the round is about to settle, the oracle game size at round , and the continuation value of future disputes. When the manipulator disputes, they earn as an internal oracle-game transfer (the profit from correcting the previous reporter’s stale price, not external notional PnL). However, as the new reporter they lose in expectation to future honest disputers. The cost term reflects the expected loss from providing new reporter liquidity (see Oracle Accuracy & Cost). This approximation may be off, as discussed in Accuracy under manipulation. Further below, in the “Incorporating self-consistent dispute barriers” section, we revisit this with the self-consistent barrier .
The continuation value can be computed using dynamic programming (backward induction). Assume dispute barriers at , a multiplier , and initial liquidity with .
Define a round cap (say 80). Technically, the net cost to dispute at round is:
which can be arbitrarily small if the settlement price is close to the dispute barrier . However, at round 80, is so large that the required closeness to the barrier relative to the external profit potential is so unlikely that we set as the base case.
Working backwards from there: at round 79, we know , so we can compute and for every possible settlement price . is still very likely astronomically large, so the attacker settles almost everything and is barely above 0. This continues for many rounds backwards: the game is too expensive, the manipulator doesn’t really dispute, is tiny.
Eventually we reach a round where is small enough relative to that delaying an unfavorable settlement is at least somewhat likely to be cheaper than eating the external loss. At this point, the attacker blocks bad outcomes (delay) and keeps good ones (settle). Each step backwards adds another chance at a favorable settlement, so grows. More precisely, at each round :
where is the probability the honest network disputes (round continues automatically) and is the probability the round survives to settlement. By round 0, reflects the full value of being able to selectively settle over all future rounds. This is the manipulator’s total expected utility, which is external extraction net of internal dispute losses:
The internal losses (dispute costs minus dispute income) are tracked separately through the recursion. Rearranging:
As a simple example, take , (L = 100k, N = 667k), , dispute barriers at , per-round survival probability , and a round cap of 80. We set as the base case for the reasons described above.
Working backwards, stays small for many rounds because the game is too expensive to dispute except for the most extreme values near the barrier. As the game size shrinks toward , delaying becomes worthwhile for a wider range of unfavorable settlements and grows. By round 12, the game size () is comparable to the notional and the attacker disputes a meaningful share of survivors. Consider (unfavorable for the manipulator wanting lower):
Delaying costs 3,606 while settling costs 6,667, so the attacker delays. But for (favorable), and delaying is deeply negative, so the attacker happily settles. Running this numerically over the conditional distribution of given survival:
82% of the time, the honest network disputes and the game continues to round 13 (the attacker gets for free). 18% of the time, the round survives and the attacker picks whichever of settle or delay is better for each .
At round 11, the same calculation uses as the continuation value. The game is slightly cheaper (), so the attacker disputes a slightly wider range of unfavorable , and . Each step backwards adds another chance at a favorable settlement while blocking unfavorable ones, and grows. By round 0, with expected internal losses (dispute costs net of dispute income) of approximately . Applying the formula:
or about of price.
We then sweep this method across different choices of initial liquidity fraction and multiplier to find the parameter configuration that minimizes expected bias. Expected bias in units of :
where approximates reporter cost as a fraction of notional (from Oracle Accuracy & Cost) and weights how aggressively bias is penalized. With (neutral weighting):
Self-dispute caveat
An attacker can try to front-run honest disputers and self-dispute to avoid the internal oracle-game losses above. If the policy is held fixed and the front-run is perfect, this just removes the internal transfer: same round count, same bias, higher net profit. But removing the internal penalty changes the optimal policy. It raises the delay value, so the attacker delays in weakly more states. This lowers the per-round settlement probability , pushing toward the cost blow-up boundary from Economic Bounds. Specifically, if the internal loss is fully avoided and the policy is unconstrained, the attacker targets settlement only in very favorable states — right below the dispute barrier in their favor — to maximize per-settlement extraction. This increases the payoff per successful settle, but crushes the per-round settlement probability. Expected rounds then scale as , and the required reporter stake grows geometrically (), making the strategy extremely brittle to any execution miss. The tradeoff is better per-hit extraction at the cost of a huge round count and capital explosion. In the real world, dispute barriers are not a fixed quantity. Different disputers have different thresholds, the manipulator cannot always get on chain first, there are discontinuous price jumps that must be bid against in discrete block units, and so on. These frictions all work against the attacker’s ability to reliably capture the dispute slot with no cost every round.Explicit transfer accounting
The stronger form section above uses a coarse reporter loss term in . Here, we replace that with explicit transfer accounting in the state machine. We use two reporter identity states: means the current reporter is honest, and means the current reporter is attacker controlled. For this formulation, we assume: if the round hits an honest dispute barrier, control transitions to honest next round ( and on hit). If the round survives and the attacker chooses delay, the attacker has control next round ( and on survive & delay). We keep the same honest barriers and same round growth . The key change is that losses are realized only when they are actually realized in the game flow. Using the stronger form notation defined above:
If a hit happens from attacker-reporter state, capture succeeds with probability . On failed capture, attacker control is lost and the reporter-side loss is realized explicitly:
With this hit transition, the value function recursions are:
Like before, bias is decomposed from total EV plus internal transfer accounting:
We first sweep this explicit transfer model at across the same and grid (round cap ).
Expected bias in units of :
Incorporating self-consistent dispute barriers
From Oracle Accuracy & Cost, the honest dispute barriers in the presence of manipulation may be different from the simpler bound. If we denote the self-consistent honest dispute barrier by , the explicit transfer DP equations become:
If a hit happens from attacker-reporter state, capture succeeds with probability . On failed capture, attacker control is lost and the reporter-side loss is realized explicitly:
With this hit transition, the value function recursions are:
Like before, bias is decomposed from total EV plus internal transfer accounting:
The key differences from the fixed-barrier model: replaces as the dispute barrier and reporter-side loss, and the survival distribution is computed at rather than . Depending on , may be wider or tighter than , changing both the survival probability per round and the loss on each dispute.
The score function also changes, from the work in Accuracy under manipulation. The reporter cost is no longer but , with as the reporter’s expected loss per unit at barrier :
We sweep this model at across the same and grid (round cap ). Expected bias in units of :
Binary notional manipulation
Delay attacks
In a binary notional application (e.g. a bet that price is above strike at some future time), the attacker’s goal is to delay oracle settlement until the true price drifts into their favor. The decision to delay triggers when:
Roughly, this compares the payoff given a breach times the chance the price moves across the threshold over the settlement time of the oracle game, against the cost to delay that round.
This is a one-step heuristic. The forthcoming full control formulation includes continuation value from future delay opportunities, as in the linear notional analysis above. The same backward induction approach applies: the attacker delays when the expected value of continuing (including all future delay options) exceeds the cost of the current delay.
The utility from a delay versus settlement can be broken down as follows. Assume zero swap fees and protocol fees. Let be the distance from the reported price to the strike, positive meaning favorable for the attacker:
where is the distance to strike after the price moves over the settlement time. As in the linear case, the attacker earns from correcting a stale price but loses in expectation as the new reporter. The continuation value captures all future delay opportunities starting from the updated price.
The continuation value is computed via the same hit-versus-survive decomposition as the linear case. During the settlement time, the true price moves by , updating . However, the oracle settles at the reported price from the start of the round, not the true price at the end. So depends on (the reported price), while depends on (the true price at time of dispute, which becomes the reported price for the next round):
where is the probability the honest network disputes and is the probability the round survives to settlement.
Because the continuation value depends on (the absolute price level relative to the strike), the distributional robustness that applies to the two-sided barrier game in the linear notional analysis does not carry over here. The binary delay problem is highly distribution-dependent.
Reducing the probability of successful delay
The probability term can be reduced by:- Strike distance: strike price far from current price at time of bet
- Maturity ratio: time to maturity of bet long relative to the oracle’s settlement time